Flash-Fusion: Enabling Expressive, Low-Latency Queries on IoT Sensor Streams with LLMs
Smart cities and pervasive IoT sensor deployments have generated significant interest in IoT data analysis across fields like transportation and urban planning. At the same time, the rise of Large Language Models offer a new tool for exploring IoT data - particularly using its natural language interface for improved expressibility. Users today face two main challenges with gathering and interpreting IoT data today with LLMs: (1) data collection infrastructure is expensive, generating terabytes daily of low-level sensor readings that are too granular for immediate use, and (2) data analysis is time-consuming, requiring time-consuming iteration and technical expertise. Directly feeding all IoT telemetry to LLMs is impractical due to finite context windows, prohibitive token consumption (hundreds of millions of dollars at enterprise scales), and non-interactive latencies. What is missing is a system that first parses the user’s query to determine the required analytical task, then selects the relevant data slices, and finally chooses the right representation before invoking an LLM.
To address these challenges, we present Flash-Fusion, an end-to-end edge-cloud system that addresses the IoT data collection and data analysis burden on users. Two core principles guide its design: (1) edge-based statistical summarization (achieving 73.5% data reduction) to tackle the data volume problem; and (2) cloud-based query planning that clusters behavioral data and assembles context-rich prompts to tackle the data interpretation problem. We deploy Flash-Fusion on a university bus fleet and evaluate against a baseline that feeds raw data directly to a state-of-the-art LLM. It achieves a 95% latency reduction and 98% decrease in token usage and costs while maintaining high-quality responses. Flash-Fusion enables personas across various disciplines - safety officers, urban planners, fleet managers, and data scientists - to quickly and efficiently iterate over IoT data without the burden of query authoring and preprocessing.
Teaser
Smart cities run on the Internet of Things (IoT), where networks of sensors stream data from roads, vehicles, utilities and public spaces, enabling city operators to make informed and timely decisions. This flow of information enriches public transportation systems, resulting in shorter trips, lower emissions and better daily experiences for residents. At the same time, Large Language Models (LLMs) have emerged as powerful tools for processing sensor data, particularly as they advance in their reasoning capabilities and support larger context windows. For example, they can interpret smartphone accelerometer data to recognize human activity, identify temperature anomalies in industrial machinery, or perform sensor fusion of optical and LIDAR data. Users are able to query LLMs using natural language, which enables highly expressive queries over data such as “Which bus routes are running behind schedule?”.
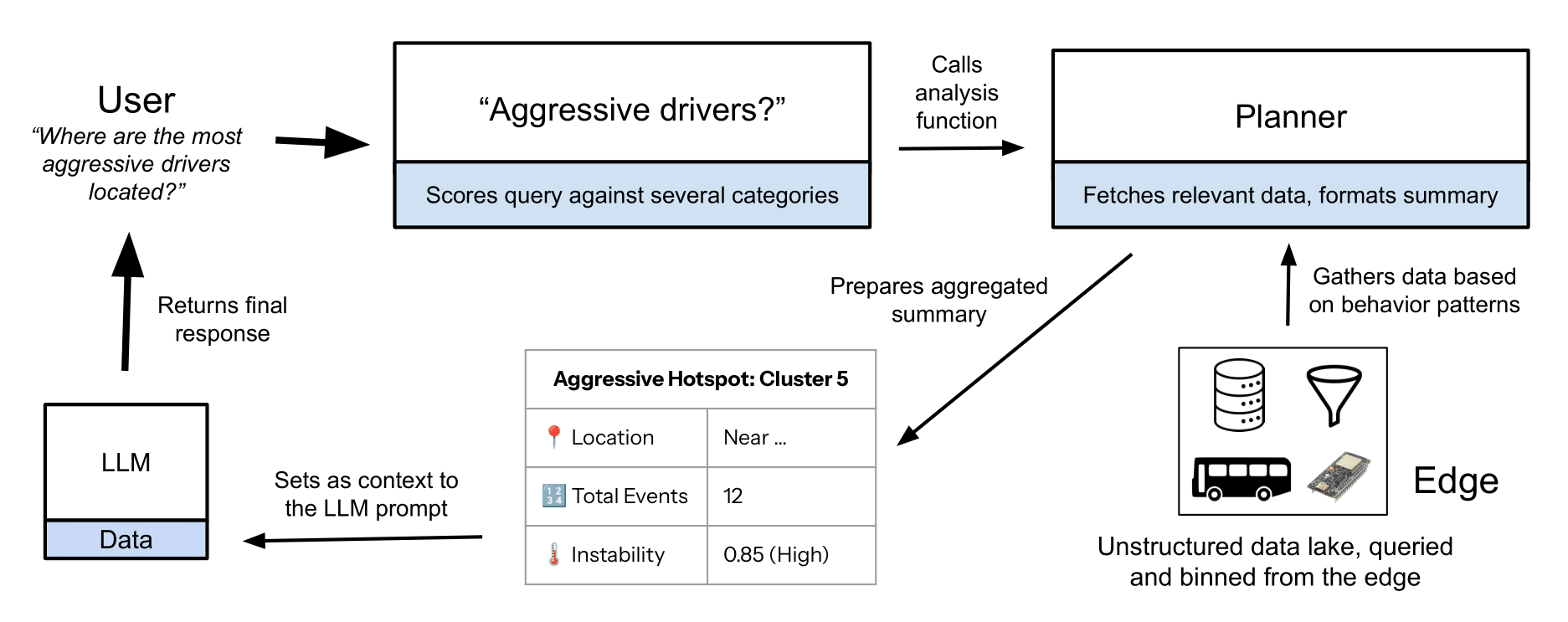
Fig. 1. Flash-Fusion: Fast, Grounded Intelligence: Sensor data are aggregated on-device, minimizing transmission overhead. Compact summaries are clustered in the cloud by behavioral type. When a user asks a question, the system analyzes their intent and fuses relevant data into the LLM prompt, yielding responses that are fast, verifiable, and grounded in real data.
Consider a fleet manager overseeing a city’s bus transit system. To improve passenger safety, the manager would like to identify aggressive driving behaviors (e.g., harsh braking and acceleration) that endanger riders. Identifying such behaviors has two main challenges:
-
Data collection is expensive. To perform the analysis on the bus transit system, the fleet manager needs to first collect sufficient data. Building a data collection network requires a significant upfront investment in hardware, connectivity, and a scalable cloud backend, with projects often spanning months and costing hundreds of thousands of dollars. The fleet manager likely needs to equip several vehicles with IoT sensors that generate a continuous stream of telemetry data, including GPS and accelerometer readings. The resulting data streams are massive - adding up to terabytes daily for city-wide fleets - and continuous, demanding real-time processing. Cities invest in Intelligent Transportation System (ITS) infrastructure hoping the data can serve multiple departments, from urban planning to public safety. Urban planners study route trends to optimize bus networks, safety officers analyze braking patterns to spot risky intersections, and fleet managers track fuel use and maintenance needs. However, the raw sensor readings are often too low-level and specific to be immediately useful across these disciplines.
-
Data analysis is time-consuming. Even after the data is collected, making sense of it to answer the fleet manager’s query is challenging. This process involves building ETL (Extract, Transform, Load) pipelines to feed sensor readings into a database, where analysts must write intricate queries to hunt for patterns. Not only is this approach slow, but it also demands deep technical and domain expertise to distinguish sensor noise from an aggressive driving event. This typically requires domain experts (e.g., the fleet manager) to sit with data analysis teams to carefully craft and iterate on queries to make sense of the data. Depending on the dataset size, this can take anywhere from hours to days.
LLMs are promising because they can ingest raw, high-volume sensor data and let both experts and non-experts explore it using natural language. This can reduce the need for complex, hand-crafted queries. In principle, a fleet manager could feed data from an IoT sensor into an LLM and ask directly about unsafe driving events instead of relying on a data science team.
Unfortunately, directly sending raw telemetry to an LLM is impractical because (1) context windows truncate long time horizons, (2) per-token costs scale linearly with data volume, and (3) latency grows with input size, making interactive use difficult. For example, an enterprise-scale IoT system may deploy millions of devices and generate trillions of data packets annually. If each JSON packet contains about 600 characters, and one token corresponds to roughly four characters, the monthly token volume would be around 1.25×1013 tokens. At standard API pricing, the monthly input cost alone would be approximately $375M. Beyond cost, finite context windows are a hard limit: even with a 106-token capacity, the window would be saturated in about 0.21 seconds at these data rates. This prevents the LLM from detecting long-term trends because most of the data is truncated. When fed noisy and contextless numerical streams, LLMs often produce plausible-sounding but incorrect answers—an unacceptable failure mode in safety-critical settings.
We make two key observations to enable data-driven IoT telemetry analysis with LLMs. On the data collection side, devices must be efficient with what they send back to the cloud. Rather than transmitting raw sensor streams, an IoT device should send short summaries of on-device readings, such as the mean and variance of acceleration over a 3-second window. However, this must be done carefully: over-filtering reduces accuracy and may require expensive re-collection. On the data analysis side, analysts lack a systematic way to explore IoT data with LLMs, making queries slow, expensive, or infeasible. We need a system that extracts the analytical task from the user’s query, identifies the relevant data, and selects an appropriate representation (such as summaries, counts, or geographic markers) before involving an LLM. This allows the model to receive a structured, compact view of the data, reducing cost while improving accuracy.
We present Flash-Fusion, an end-to-end system that lets users ask high-level questions about IoT data and receive accurate responses with low latency and low cost. During data collection, the edge compresses raw streams into fixed-window statistical summaries—mean and variance of acceleration magnitude, high-percentile axes, and GPS/time context—before transmission. This summarize-at-source design, common in edge computing, reduces transmission by 73.5% in our study while preserving key features needed for behavior analysis.
Once this condensed data reaches the cloud, the challenge shifts to interpretation: users want insights but may not know how to query complex IoT datasets. To reduce user burden, the cloud-side planner identifies the analytical task implied by the user’s question (e.g., detecting the keyword “dangerous” to trigger an Aggressive Driving analysis) and fetches the matching data representation. Flash-Fusion bridges the gap between qualitative user queries (such as smoothest ride) and quantitative sensor signals (like accelerometer readings). After the firmware summarizes and transmits the data, a serverless backend clusters it into driving profiles ranging from Calm to Very Aggressive. At query time, the planner retrieves only the relevant cluster summaries, anchors them to campus landmarks, and assembles a compact, context-rich prompt that provides the LLM with the background it needs to generate accurate and nuanced responses.
Flash-Fusion enables a wide range of users—safety officers, urban planners, fleet managers, and data scientists—to explore IoT data quickly and efficiently without manual scripting or data wrangling.
We demonstrate Flash-Fusion’s performance using real deployments on a university bus fleet. Across a variety of real-world queries from different personas, the system achieves a 95% latency reduction and a 98% decrease in token usage and API cost, while maintaining reliable, high-quality responses compared to a state-of-the-art 8B-parameter model.
In summary, our primary contributions are the following:
- A characterization of current limitations in applying LLMs to large-scale IoT telemetry using real vehicular data.
- The design and implementation of Flash-Fusion, an end-to-end system that integrates on-device data reduction, serverless cloud-based clustering, and an LLM-powered planner to automate the data-to-insight pipeline for IoT analytics.
- A quantitative and qualitative demonstration of Flash-Fusion’s ability to reduce latency and cost while maintaining factual consistency compared to naïve, raw-data prompting of state-of-the-art LLMs.
- The collection and development of a vehicular transportation dataset and application that we will open-source upon acceptance, broadening the scope of analysis possible for smart city transit systems.
Full paper can be found here.